Publication
* denotes equal contribution and joint lead authorship.
Filter by Tag:
2025

ResearchTown: Simulator of Human Research Community.
In ICML 2025–International Conference on Machine Learning 2025.
Large Language Models (LLMs) have demonstrated remarkable potential in scientific domains, yet a fundamental question remains unanswered: Can we simulate human research communities with LLMs? Addressing this question can deepen our understanding of the processes behind idea brainstorming and inspire the automatic discovery of novel scientific insights. In this work, we propose ResearchTown, a multi-agent framework for research community simulation. Within this framework, the human research community is simplified and modeled as an agent-data graph, where researchers and papers are represented as agent-type and data-type nodes, respectively, and connected based on their collaboration relationships. We also introduce TextGNN, a text-based inference framework that models various research activities (e.g., paper reading, paper writing, and review writing) as special forms of a unified message-passing process on the agent-data graph. To evaluate the quality of the research simulation, we present ResearchBench, a benchmark that uses a node-masking prediction task for scalable and objective assessment based on similarity. Our experiments reveal three key findings: (1) ResearchTown can provide a realistic simulation of collaborative research activities, including paper writing and review writing; (2) ResearchTown can maintain robust simulation with multiple researchers and diverse papers; (3) ResearchTown can generate interdisciplinary research ideas that potentially inspire novel research directions.
2024

DeFT: Decoding with Flash Tree-Attention for Efficient Tree-structured LLM Inference.
In International Conference on Learning Representations (ICLR) Spotlight(Top 5%), abridged in ICLR’24 workshop AGI (Oral). 2024.
Large language models (LLMs) are increasingly employed for complex tasks that process multiple generation calls in a tree structure with shared prefixes of tokens, including few-shot prompting, multi-step reasoning, speculative decoding, etc. However, existing inference systems for tree-based applications are inefficient due to improper partitioning of queries and KV cache during attention calculation.This leads to two main issues: (1) a lack of memory access (IO) reuse for KV cache of shared prefixes, and (2) poor load balancing.As a result, there is redundant KV cache IO between GPU global memory and shared memory, along with low GPU utilization. To address these challenges, we propose DeFT(Decoding with Flash Tree-Attention), a hardware-efficient attention algorithm with prefix-aware and load-balanced KV cache partitions. DeFT reduces the number of read/write operations of KV cache during attention calculation through KV-Guided Grouping, a method that avoids repeatedly loading KV cache of shared prefixes in attention computation. Additionally, we propose Flattened Tree KV Splitting, a mechanism that ensures even distribution of the KV cache across partitions with little computation redundancy, enhancing GPU utilization during attention computations. By reducing 73-99% KV cache IO and nearly 100% IO for partial results during attention calculation, DeFT achieves up to 2.23/3.59x speedup in the end-to-end/attention latency across three practical tree-based workloads compared to state-of-the-art attention algorithms.
2023
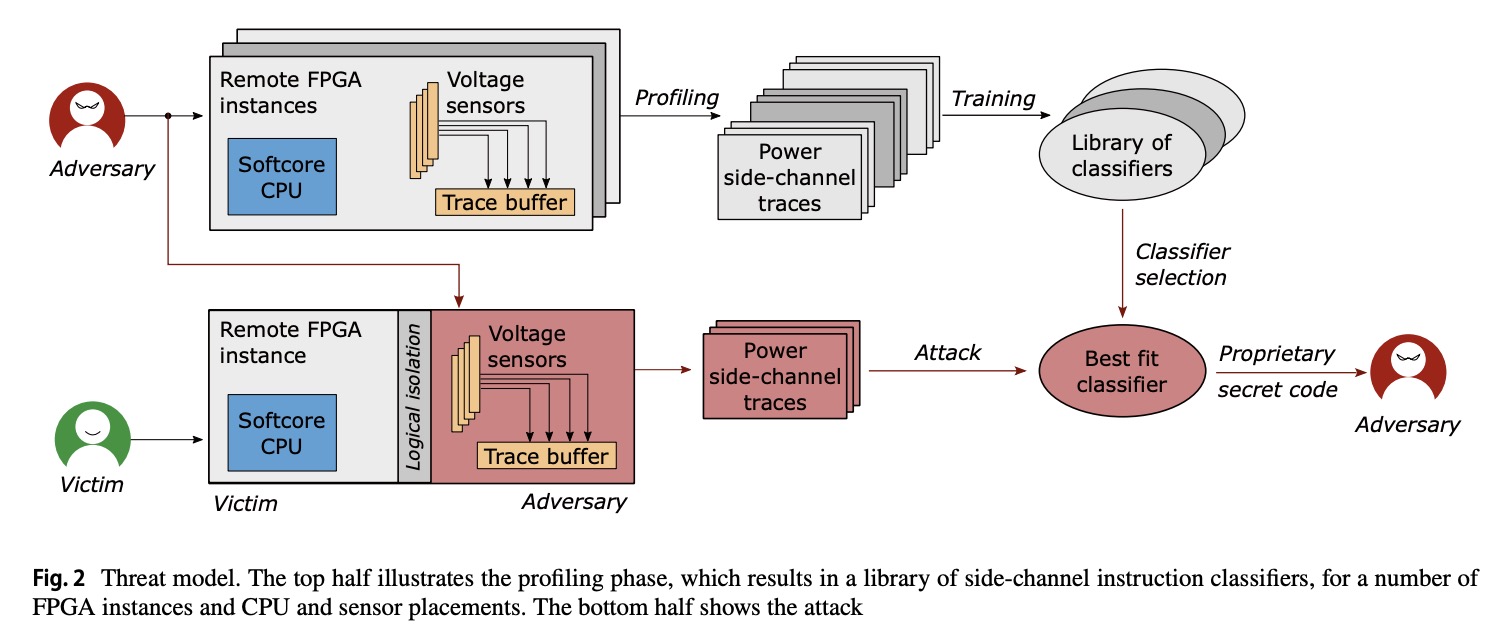
Instruction-level power side-channel leakage evaluation of soft-core CPUs on shared FPGAs.
In Journal of Hardware and Systems Security 2023.
Side-channel disassembly attacks recover CPU instructions from power or electromagnetic side-channel traces measured during code execution. These attacks typically rely on physical access, proximity to the victim device, and high sampling rate measuring instruments. In this work, however, we analyze the CPU instruction-level power side-channel leakage in an environment that lacks physical access or expensive measuring equipment. We show that instruction leakage is present even in a multitenant FPGA scenario, where the victim uses a soft-core CPU, and the adversary deploys on-chip voltage-fluctuation sensors. Unlike previous remote power side-channel attacks, which either require a considerable number of victim traces or attack large victim circuits such as machine learning accelerators, we take an evaluator’s point of view and provide an analysis of the instruction-level power side-channel leakage of a small open-source RISC-V soft processor core. To investigate whether the power side-channel traces leak secrets, we profile the victim device and implement various instruction opcode classifiers based on both classical machine learning algorithms used in disassembly attacks, and novel, deep learning approaches. We explore how parameters such as placement, trace averaging, profiling templates, and different FPGA families (including a cloud-scale FPGA) impact the classification accuracy. Despite the limited leakage of the soft-core CPU victim and a reduced accuracy and sampling rate of on-chip sensors, we show that in a worst-case scenario for the evaluator, i.e., an attacker breaching physical separation, we can identify the opcode of executed instructions with an average accuracy as high as 86.46%. Our analysis shows that determining the executed instruction type is not a classification bottleneck, while leakages between instructions of the same type can be challenging for deep learning models to distinguish. We also show that the instruction-level leakage is significantly reduced in a cloud-scale FPGA scenario with higher soft-core CPU frequencies. Nevertheless, our results show that even small circuits, such as soft-core CPUs, leak potentially exploitable information through on-chip power side channels, and users should deploy mitigation techniques against disassembly attacks to protect their proprietary code and data.